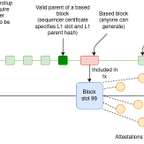
I'm now more supportive of native Rollups than before.
A major reason I previously opposed them was that native Rollup pre-compiled versions require either "Zero-Knowledge Mode" or "Optimistic Mode," and ZK-EVM wasn't mature enough to support ZK mode. Therefore, if we gave L2 servers two options: "Withdrawals take 2-7 days but require sufficient proof of trust from Ethereum" and "Instant withdrawals but require self-provided proof," they would almost certainly choose the former. This is very detrimental to Ethereum's composability, and we'll see more multi-signature bridges adopted, etc.
But now it seems that the timeline for Ethereum to fully adapt to L1 server zero-knowledge mode, and the realistic timeline for adding native Rollup pre-compiled versions, actually aligns. So, the problem is solved.
Furthermore, I'm seeing more and more work using synchronous composability as a core value proposition of "Why do L2 testing?" (I previously suggested combining Rollup-based testing with the low latency of L2 pre-configuration).
Therefore, this feels like the right direction.
I believe we should be proactive and invest more effort in exploring the right approach to pre-compilation. A key feature I'd like to see is that if you create an EVM + some new features Rollup, you should be able to use EVM's native Rollup pre-compilation capabilities and introduce your own validator that runs only for your new features. Perhaps a lookup table could be used to connect the two in a standardized way.