





















作者:CertiK
1. OpenClaw、Skill与核心隐患
OpenClaw是一款开源、自托管的个人AI智能体平台,专为在本地设备或服务器上运行设计,支持长期记忆、自主运行、与主流大语言模型(LLM)集成,还可通过Telegram等即时通讯平台实现远程控制。在实际应用中,OpenClaw的核心定位是代表用户执行操作。根据部署方式的不同,它可访问本地文件、调用工具、连接外部服务,以及在宿主环境(Host Environment)内执行命令。
如果把OpenClaw比作底层操作系统,那么Skill就是它上面的应用程序。Skill能够拓展智能体的能力边界,从网页搜索、社交内容发布等低风险任务,延伸至钱包操作、链上交互、系统自动化等高度敏感的领域。Skill在同一个运行时环境(供Skill代码运行、调度系统资源的专属环境)中执行,可能继承对本地资源、网络连接和工具接口的访问权限。
在高权限的智能体环境中,即便核心平台本身可信,也不能简单默认第三方Skill是安全的。而行业针对这一问题的通用解决方案,就是Skill扫描。
2. Clawhub如何审核Skill?
随着OpenClaw生态的不断扩张,Clawhub自然而然成为了其生态的应用市场层:开发者发布Skill,用户安装下载,整个生态通过第三方扩展持续壮大。
一旦平台开始分发运行在高权限环境下的第三方代码,某种形式的审核就变得不可避免。Clawhub也正是朝着这个方向发展,其审核流程从最初轻量化的信任模型,逐步演变为一套分层管控流程,已涵盖VirusTotal、基于AI的内部审核;以及于2026年3月8日在公共代码仓库上线的静态审核引擎。
从宏观来看,Clawhub目前的审核流程主要结合两大检测来源:VirusTotal与OpenClaw内部的审核系统。这两类扫描结果共同决定Skill的风险分类,以及用户在安装过程中是否会看到安全警告。
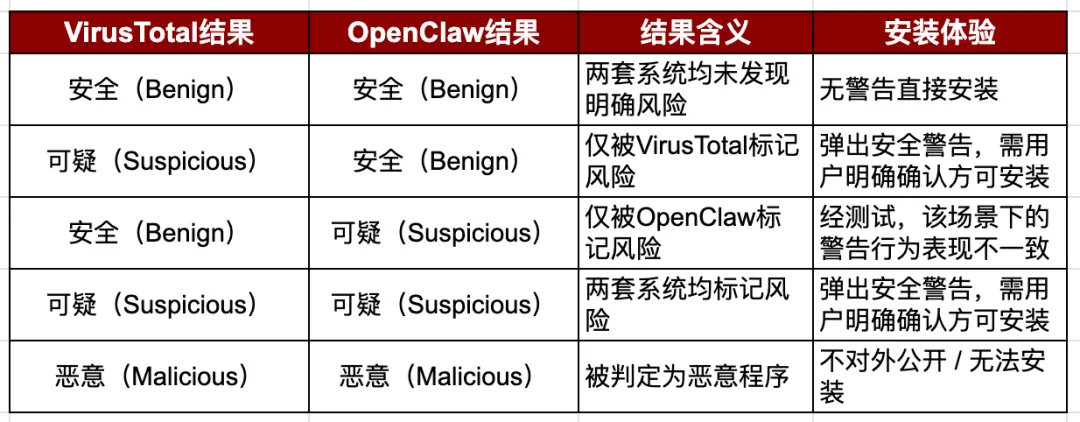
这一设计体现了行业内常见的一种权衡取舍:既要保持生态的开放性,又要向用户提示风险信号。一旦安装决策依赖于弹窗提示和用户确认,安全警告就开始承担部分安全防护的职责。而这一模式生效的核心前提,是运行时底层已经实现了有效的隔离机制。
面对这一问题,最直观的应对策略是增加更多的扫描、分类器和安全警告。但问题的核心,并非如何更精准地检测恶意Skill。扫描的确有助于风险分级,却无法成为安全边界。就像苹果公司并非仅靠App Store的审核来保障其生态安全,其核心依托的是操作系统强制实现的沙箱机制、权限管控与环境隔离。这一原则在此处同样适用:如果审核和弹窗提示承担了绝大部分防护工作,就说明运行时边界的防护作用严重不足。
OpenClaw确实具备沙箱机制和运行时管控的能力;但问题在于,这些能力主要是可选而非强制、管控粒度过粗,且高度依赖部署配置,无法作为第三方Skill的默认安全边界。OpenClaw官方文档也明确说明:基于Docker的沙箱机制是可选功能;沙箱关闭时,宿主工具仍可被调用;沙箱部署位置、工具策略、高权限宿主执行权限,均为独立配置项。
此外还存在一个实际部署层面的问题:如果一款沙箱使用门槛高、需要用户反复确认,或是会导致大量常用Skill功能失效,那么它在实际应用中就很难成为默认运行模式。用户和运维人员往往会为了保证系统可用性,放弃使用沙箱。而一旦出现这种情况,平台就只能退而依靠审核和警告,去承担它们从一开始就无力承载的安全防护重任。
3. 静态检测与其局限性
截至2026年3月8日(UTC时间),Clawhub的公共代码仓库已上线静态审核引擎,同步推出的还有结构化审核快照,以及整合后的VirusTotal与大语言模型检测结果处理机制。
该引擎的核心入口为moderationEngine.ts[1]字中的runStaticModerationScan(),代码检测的核心逻辑则位于scanCodeFile()中。
相比传统安全产品通常处理的输入对象,Skill的扫描难度更高,因为它们混合了代码、自然语言、清单文件、指令、工具调用逻辑和运行时行为。在这里,检测盲区绝非偶然现象,它们是该问题与生俱来的顽疾。
静态规则主要检测特定风险模式,例如:child_process与进程创建API、; margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; vertical-align: bottom; height: auto !important; visibility: visible !important; width: 624px !important;"/>
公开的安全Skill self-improving-agent顺利安装,未触发任何警告,这在我们的预期之内。我们定制的test-web-searcher,在VirusTotal仍处于待处理状态时,同样在无有效安全警告的情况下完成了安装。与之形成对比的是,公开的Skill clawpay-escrow却触发了安全弹窗,需要用户明确确认方可安装。
随后,我们通过Telegram向OpenClaw发送指令,调用了test-web-searcher。漏洞导入路径被成功触发,最终在宿主设备上实现了任意命令执行。在演示环境中,我们成功弹出了计算器程序,以此作为完成任意命令执行的证明。
这个存在漏洞的Skill,安装流程与安全Skill毫无差别。无论是通过命令行还是Telegram安装,全程都没有出现有效的安全警告。这暴露了问题的核心:审核信号被当作了真实安全边界的替代品,而一款高风险Skill,在安装环节的表现,却可以与安全Skill完全一致
6. 检测机制失效的根本原因
我们设计的测试用例,并非复杂的对抗性样本。我们只是植入了一个漏洞,仅通过轻量级的代码变换来降低被检出的概率。真实的攻击者会做得更绝:他们会极其谨慎地隐藏攻击路径,将恶意逻辑伪装得贴近正常代码,以及针对审核流程做专门的对抗优化。绝不仅仅是“标为可疑却仍可安装”,而是那些被植入后门、却能成功骗过双层审核机制的危险Skill。
我们的概念验证已经足以勾勒出问题的严重性:静态检测规则可以通过代码重写绕过;AI审核虽有辅助作用,但相比于从看似合理的工作流中全面挖掘可利用逻辑,它显然更擅长曝光那些明显的危险信号;而依赖于非强制沙箱、部署规范或用户手动加固的运行时控制机制,根本无法可靠地阻止这些漏网的恶意代码入侵宿主设备。
综上,这些并非孤立的安全弱点,而是重度依赖审核的安全模型的必然局限。
检测机制依然有其存在的价值,它可以降低安全噪音、捕获低水平的恶意攻击,以及发现值得深入调查的风险信号。然而,捕捉可疑信号是一回事;要为运行在高权限环境下的第三方代码(Skill),设下一道真正的安全防线,则完全是两个概念。
平台必须树立底线思维,默认必定会有漏网的危险Skill成功渗透。一旦接受了这个前提,真正的核心问题就不再是“如何增加更多的审核环节”,而是“运行时是否能够遏制这些漏网的风险”。
目前,过高的安全期望仍被寄托在检测机制上,而检测机制注定无力承担此重任。
7. 安全建议与结论
对于AI智能体开发者而言,核心优先级非常明确:在扩大对Skill审核的信任之前,先强化运行时的安全能力。
首先,沙箱隔离应当成为第三方Skill的默认配置。第三方代码必须默认运行在隔离环境之中,而不应仅仅依赖于用户或运维人员手动选择加固系统时才启用。
其次,运行时环境应强制执行基于Skill的权限模型。每个Skill都必须在启动前预先声明其所需的资源与权限,运行时在执行环节严格管控权限的使用,这一逻辑与现代移动操作系统的做法一致。绝不允许第三方Skill从宿主机环境中直接继承宽泛的信任权限。
对于终端用户而言,核心结论更为简单:“安全”标签绝非安全的证明。它仅意味着当前的审核流程,未以改变安装流程的方式标记该Skill存在风险。在强隔离机制成为默认配置之前,仅建议将OpenClaw部署在低价值环境中,远离敏感文件、凭据信息以及高价值资产。
从更宏观的视角来看,问题的核心并非扫描器需要优化,而是审核机制被要求承担了过多的安全防护职责。审核可以协助风险分级、捕获明显的恶意攻击,但绝不能成为高权限智能体的核心安全保障。真正的安全,始于平台预设一定会有危险Skill绕过审核,并通过运行时的设计,确保这些漏网的风险不会立刻导致宿主设备被攻破。真正关键的转变,从“追求完美检测”转向务实的“实现损害遏制”。




No Comments